[ICLR 2023] MASKFUSION: FEATURE AUGMENTATION FOR CLICK-THROUGH RATE PREDICTION VIA INPUT-ADAPTIVE
摘要
这篇论文提出了一个自适应特征融合框架,称为MaskFusion,以额外捕获显式的交互分析了输入特征与现有深部CTR结构之间的关系动态建模,除了现有的共同特征的相互作用的工作原理。
MaskFusion是一种实例级别的粒度的感知,用于对提取的信息进行增强,使深度CTR模型更加个性化,通过分配每个特征与实例自适应掩码和融合每个特征与每个隐藏状态向量深部结构。MaskFusion使用起来也比较灵活,可以集成到任何现有的深度CTR模型当中。
模型结构
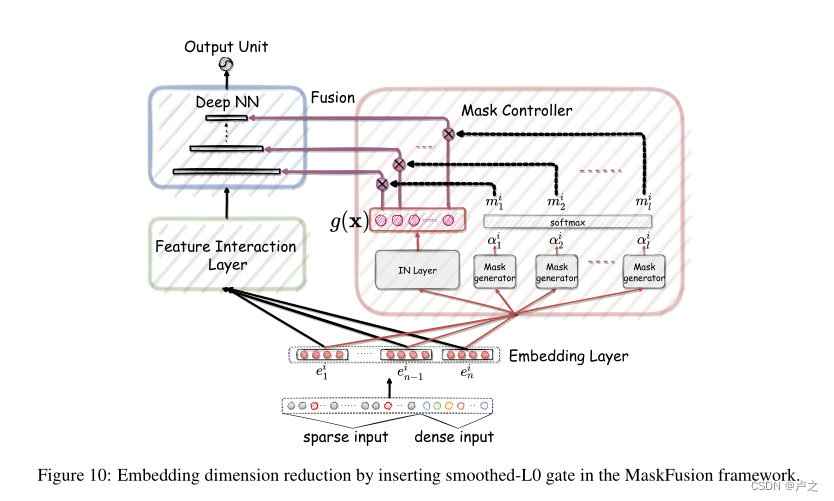
核心方法
该论文的核心方法主要有三部分,接下来会分成这三部分去说明每个组件的作用。
Fusion Layer
Mask Controller
Instance Norm Layer
Fusion Layer
Fusion Layer主要的作用就是用来与NN层进行交互,作为融合的手段,论文当中选取的方式是 Concat。论文当中的解释为,如果使用element-wise的交互方式,很难对特征的可解释性有所贡献,言下之意就是concat的方式能够比较明确将增益部分做出归属判断。
$$\mathbf h_t=Relu(\mathbf W_t \mathbf{\hat{h}}_{t-1}+\mathbf{b}_t)$$
$$\hat h_t=Concate([E,Relu(W_t\hat{h}_{t-1}+b_t)])$$
Fusion Layer 的还有提升模型的记忆能力,但是会对所有的实例级别的数据无差别的进行融合交互,忽略掉实例之间的差异。另外就是提高了记忆能力就会降低模型的泛化能力。于是,论文就设计了第二个模块,Mask Controller。
Mask Controller
Mask Controller的作用在于基于每个实例的全局信息自动生成Mask,并且在Fusion Layer的融合过程中对生成的Mask进行应用。
这里的Mask处理意味着能够融合过程中能够进行更好的记忆,我们也能够知道哪些特征能够更好地作用于CTR预测,同时意味着具有很强的可解释性。
在论文当中,使用MLP作为演示,用来生成Mask,公式如下:
$$\boldsymbol\alpha_t^k=MLP_{\boldsymbol\phi_t}(\mathbf E)$$
注意公式中的下标,下标意味着对每个实例 $k$ 都有第 $t$ 个mask生成器,生成器的个数,与即将交互的DNN的层数相同。
为了学习哪些特征更有助于网络记忆,以及更好地进行训练收敛,论文当中采用了 $softmax$ 的激活函数对 mask 进行normalize。
公式如下:
$$m_{t,j}^k=\dfrac{exp(\alpha_{t,j}^k)}{\sum_{t=1}^l exp(\alpha_{t,j}^{k})},~\forall j\in[1,n],~\forall t\in[1,l]$$
Mask生成好之后,对特征向量进行相乘,然后与主网络每层的输出进行级联,送到下一层。
$$ \mathbf{\hat h_t}=Concate([\mathbf m_t^k \mathbf E,\mathit Relu(\mathbf W_t \mathbf{\hat h_{t-1}}+\mathbf b_t)]) $$
Instance Norm Layer
论文中认为,Mask的效果可能被重缩放所影响,为了消除这种现象,在消失重缩放的过程中保留每一位的信息。 Batch Norm 以及 Layer Norm 都不能适用这个问题,因为BN的计算是计算一个小批量中所有实例的信息,LN的计算是计算一个实例中所有特征的信息。
论文当中使用了实例级别的Norm,被称为Instance Norm,公式如下:
$$IN(\mathbf e_j^k)=\gamma\cdot\dfrac{\mathbf e_j^k-\mu_j}{\sqrt{\sigma_j^2+\epsilon}}+\boldsymbol\beta$$
这里的BN LN IN的理解,可以参考这篇文章
总结
这种方式基本上属于万金油的trick优化方式,提升Mask的准确性以及泛化性,适用于各个以DNN为基础的推荐系统,也属于比较好工程实现的方式。